Poor Quality Data is Hurting Your Attribution. Here’s Why…

As marketers strive for a clearer view of what is and isn’t working in their marketing mix, the focus is usually on finding the right attribution model to meet their needs.
But while choosing the right attribution model is important, the quality of the underlying data feeding into it is equally important, if not more so. To put it simply; a low-quality input results in a low-quality output, and it’s on this output that marketers are basing important decisions around spend.
The problem is that most of our core marketing data is inherently flawed. This stems from serious shortcomings with the process of collecting and analysing data from a range of channels including website, offline, social and mobile.
So, what exactly are these flaws and what challenges do they present to marketers?
We break it down for you below.
Web data: The limitations of the cookie/pixel approach
The vast majority of website user data is what’s called ‘deterministic data’.
Pixels and cookies generate data that’s around 80% incorrect, and traditional analytics platforms are unable to attribute it.
Deterministic data, or first party data, is essentially data that is known to be true. It’s based on unique identifiers that match one user to one dataset, and for our purposes it’s usually collected using a pixel working in tandem with a cookie.
A variety of data is captured in this way, including:
- Measurement of dwell time (how long a user spends on a page after clicking it in the search results)
- Previous sites the user visited
- Ad campaigns encountered by the visitor
- Repeat visits from the same person
Unfortunately, due to inherent flaws with this collection method, this is where the world’s most commonly used analytics solutions start to break down and generate incorrect or incomplete data.
The problem with pixels and cookies is that they track the behaviour of a device rather than a person.
This fails to account for:
- The fact that one device (i.e. a mobile or a laptop) can be used by more than one person.
- Most people use more than one device to browse the internet, including in their journey to a transaction.
This means the data doesn’t truly reflect the complex nature of a customer’s journey. And this is the data being fed into platforms like Google 360 and Adobe Analytics.
On top of this, cookies are also pretty poor at accurately ‘joining’ data generated by multiple sessions from one device, resulting in broken sessions data.
All this means that pixels and cookies generate data that we estimate to be around 80% incorrect, and traditional analytics platforms are unable attribute it.
Have a look at the graph below for an example of this:
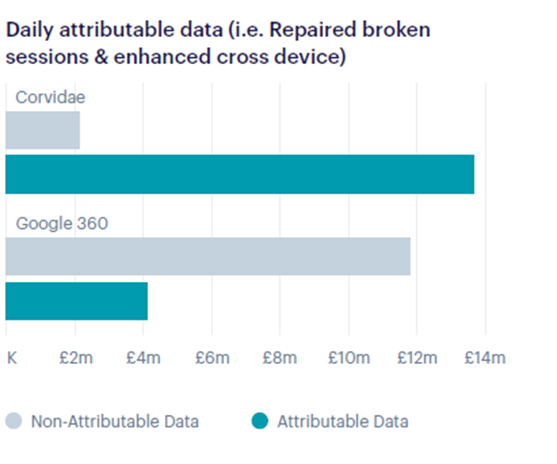
And it doesn’t stop there. Inherent flaws with the underlying data have serious implications on the accuracy of data from other channels too.
Offline: Difficulties collecting offline data
For most businesses, marketing activity includes a blend of both online and offline activity. But marketers are also facing challenges collecting and integrating offline data.
While offline data offers increasingly rich insights into user behaviour (especially with new methods of measurement like Beacon technology, opt-in WiFi tracking, and RFID data), the largest offline touchpoints – TV and Radio – rely on econometrics data.
Econometrics data presents marketers with a few challenges:
- They’re unable to look beyond channel-level impact for A/B channel or messaging strategy adjustment.
- Econometrics data operates in a silo to all other data collection strategies, resulting in cannibalisation. This makes it difficult to get an accurate integrated view.
- There’s a lack of immediacy in delivering data outcomes.
- It’s expensive and is less suited to smaller budget media spends.
It’s also very difficult to measure the impact of online campaigns on offline customer behaviour, and existing analytics solutions don’t do this effectively. With these limitations combined, marketers are left with questionable offline data that sits in a silo and therefore fails to truly understand the influence online and offline promotions have on each other and overall consumer behaviour.
Mobile & social: Challenges with accurate data
Challenges with mobile app data
In-app mobile data collection is generally considered a robust measurement environment as data is tightly associated with an individual’s login.
However, this data isn’t enough to paint an accurate portrait of user behaviour on its own. It doesn’t look at what brought a user to an app in the first place, meaning you have no visibility over the role played by earlier touchpoints.
In order to “activate” its full potential, you have to connect it with web data for the same user. And this is where the challenge comes in.
Because that underlying web data is inherently flawed (as we discussed before), it pulls down the overall quality of the mobile app and web data combined. To put it simply, stitching mobile app data to inaccurate web data gives you a mostly inaccurate result.
Challenges with social data
Similar challenges present themselves for social data, but they’re compounded by problems with this data-collection phase too.
Practical issues with how social platforms utilise the “share” function across web properties, combined with the fact that a significant amount of retargeting activity occurs against social platform pixels, means that users are often further down the conversion path than the data suggests.
In addition, social platforms typically take a “walled garden” approach to data availability outside of their own analytics. Read – they only give you a limited view.
These challenges don’t take away from social data’s potential to provide hugely valuable and rich customer insight. Marketers just need a smarter analytics solution than is offered by traditional platforms to unpick it, and data to join it to that they can trust.
Fingerprinting and the death of the third party cookie
A popular way for marketers to ‘stitch’ together web, app, and social data for a complete picture of the user journey is by using fingerprinting.
A popular way for marketers to ‘stitch’ together web, app, and social data for a complete picture of the user journey is by using fingerprinting.
Fingerprinting is a method of online tracking used to identify users who have interacted with certain marketing touchpoints. It uses publicly available device or user attributes to create a “fingerprint”, which can then be matched to subsequent visits.
There are two main types of fingerprinting; device-led fingerprinting and canvas fingerprinting.
What is device-led fingerprinting
Device-led fingerprinting focuses on device data (i.e. mobiles, laptops, etc.), identifying unique attributes for each device that it can match to future interactions and visits. There’s a lot of data available to do this, and it’s considered a highly accurate way of joining multiple sessions together.
What is canvas fingerprinting?
Canvas fingerprinting is another method of tracking users’ browser behaviour by letting websites identify and track visits using the HTML5 canvas element.
When a user visits a website, their browser is instructed to “draw” a hidden line of text or 3D token that is used to measure the characteristics of their GPU model, operating system, and overall system performances. This unique data generates a ‘digital token’ that’s used to identify the user for future visits.
When used together, canvas and device-led fingerprinting can provide a highly-accurate representation of a user’s journey.
The death of the third party cookie
Unfortunately for marketers, the impending death of the third party cookie is likely to make fingerprinting a practice of the past.
Accurate fingerprinting relies on 3rd-party cookies to collect data, which are already blocked by Safari and the majority of iOS devices citing privacy concerns. To make this worse, the world’s most popular browser, Google Chrome, is set to follow-suit and block third party cookies by 2023.
Leveraging the wealth of data in your CRM, CDP & ERP
Marketers also have access to a wealth of Customer Relationship Management (CRM), Customer Data Platforms (CDP), and Enterprise Resource Planning (ERP) data to leverage for their customer insight. This data is also considered highly accurate as customer identification or sign-in is usually a pre-requisite.
What is CRM data?
Customer Relationship Management technology is used to manage interactions with existing and potential customers. It includes tools for things like contact and sales management and can provide a wealth of valuable data around what makes customers more likely to convert, and what helps encourage repeat transactions.
What is CDP data?
Customer Data Platforms can provide equally valuable insight into what makes users tick. A CDP is a type of software that lets marketers create a unified record of all their customers, their unique attributes, and their data. A good CDP creates a complete picture of customers on an individual level.
What is ERP data?
Enterprise Resource Planning software is used to manage day-to-day activities such as accounting, procurement, project and risk management, and more.
This can include activities with the potential to collect valuable customer data insight, such as;
- Clubcard schemes
- Point of Service (POS) transaction data
- Inventory and stock availability data
- Returns and fulfillment cost data
When complemented by third party data associated with customer profiles, it can help drive:
- High-quality segmentation and cohort analysis
- Marketing automation to improve conversion and engagement rates
- A deeper understanding of marketing ROI.
What are the challenges?
The challenge here is less about the quality of data available to marketers, but the quantity. The sheer volume of data can be difficult for marketers to get their heads around.
The challenge is with the quality of data, not just quality.
To realise its full potential, they must first make sense of it and figure out how to combine it with other data sources to identify the best messaging or medium for their target audience.
While some companies have the resource and knowledge to do this well, others do not.
Once again, the inherent flaws with underlying marketing data comes into play here too. Combining CRM, CDP, and DRP data with other data sources is essential to pulling the best insight. But if that underlying data is of a low quality, then those insights will be too.
How can marketers address these challenges?
You’ve probably noticed a consistent theme running through the challenges presented in this article. Many of the data challenges faced by marketers lead back to concerns over the quality of their core underlying data.
Whilst valuable data can be collected from offline, social, and mobile-app channels, as well as insight from CRM, CDP and ERP technology, they’re not enough to paint an accurate picture of the user journey on their own. But when they’re combined with the flawed web data, their overall quality is compromised.
This is the same problematic data that traditional analytics platforms feed into their (equally flawed) attribution models, giving marketers a low-quality output on which they’re forced to base important decisions around marketing spend.
The good news is there’s an alternative approach.
Introducing Corvidae
Our attribution solution, Corvidae, is the result of years of experience in digital marketing, and a recognition of the need to tackle issues with underlying data quality.
Corvidae’s first action is to use machine learning technology to completely rebuild the data from the ground up, deploying a combination of random forest probabilistic modelling and regression analysis.
In simple terms, random forest is a classification algorithm consisting of multiple decision trees, which are essentially a map of possible outcomes for a series of related choices.
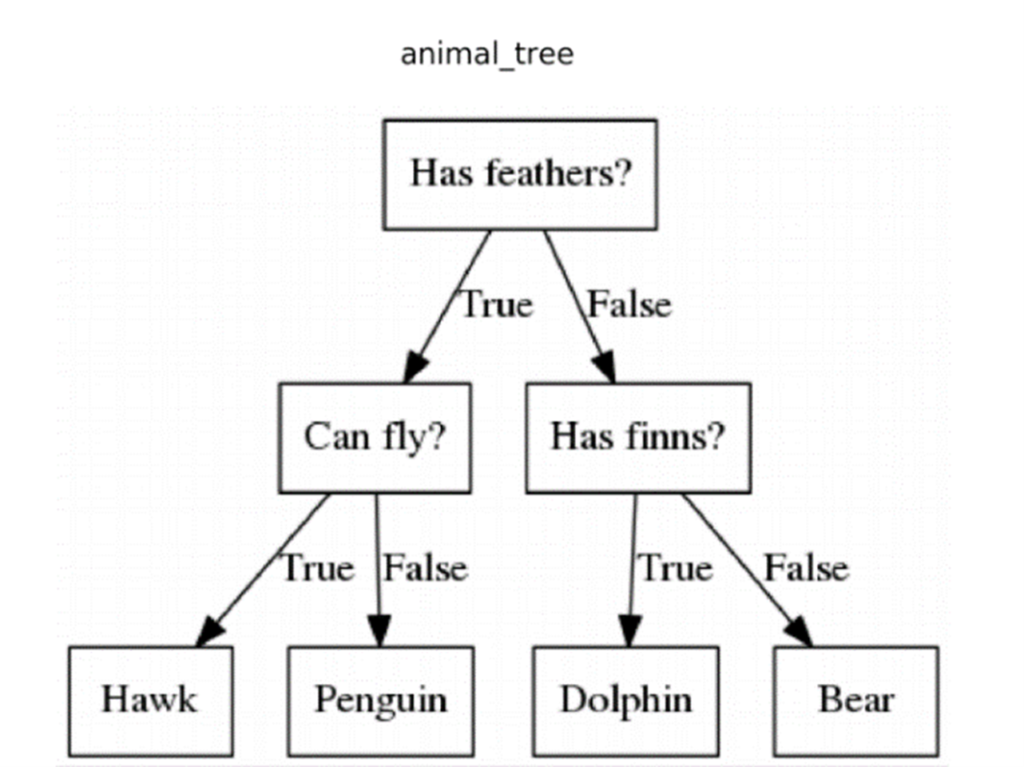
Random forest combines many of those decision trees into a single model, allowing it to make more accurate predictions based on the possible outcomes of lots of different choices.
Regression analysis is a powerful statistical method that lets you explore the relationship between two or more independent variables on one dependent variable. Again, this results in much more accurate predictive modelling.
These methods result in a core data output that enriches, rather than compromises, the cross-channel data it’s combined with.
What about the challenges unrelated to core data?
We’ve mentioned a few challenges that don’t directly relate to flawed core data, including offline econometrics data and fingerprinting. Here’s how Corvidae can circumvent them:
A new way to measure your offline impact
Corvidae solves the problem of clunky offline data with a whole new approach to measuring offline campaigns.
Corvidae seeks to solve the problem of clunky offline data by taking a whole new approach to measuring offline campaign impact.
Instead of relying on econometrics data, Corvidae analyses and learns from customer response data to online campaigns. It identifies signals that suggest a positive response, including traffic and data upticks for certain products – and the dates and times of the day they occurred.
Having identified how online customers respond to online campaigns – including how long they take – Corvidae applies these learnings to measure the impact of offline campaigns.
Using the same methodology, it looks for positive signals that suggest an uptick in sales – both online and in-store – resulting from offline marketing activity. It’s even designed to account for “real-life assumptions” like store opening hours and travel time.
This is an entirely new approach to measuring offline marketing impact that has the potential to return promising results.
And fingerprinting?
The challenge with fingerprinting is that it relies on a method of data collection that will soon be redundant. That is, the collection of device data using third party cookies.
Corvidae doesn’t have this problem because it doesn’t use third-party data to join together sessions. Corvidae deploys its own pixel that, after some quick tweaks from the customer, makes it first-party.
Summary
The key takeaway here is that many of the challenges marketers face with collecting and leveraging cross-channel data stem from fundamental flaws with the accuracy of their underlying web data.
When combined with customer data from other channels – including social, mobile, and offline – the resulting dataset is compromised.
Unfortunately, this is the approach taken by the most popular analytics and attribution platforms, including Google 360 and Adobe Analytics. And the problem doesn’t stop at data collection – these same platforms use attribution models with serious limitations that further lessen the quality of their output.
The result is that marketers are forced to rely on poor-quality and inaccurate data to make important decisions around spend.
But it’s not all bad news! There are alternative analytics and attribution platforms to turn to – including our solution Corvidae – that confront these challenges head-on. The onus is now on marketers to invest in solutions they can trust.
Get an attribution solution you can trust and speak to us about Corvidae today.




